Experimental Results
Failure Beyond
Distribution
While transformers achieved strong in-distribution validation performance, their behavior collapsed under longer out-of-distribution sequences, revealing reliance on statistical locality rather than structural rule learning.
Validation Dynamics
Models appear stable during training, but stability alone does not imply abstraction.
Both classification and next-token models demonstrate smooth validation convergence during training. However, later experiments reveal that this apparent success does not transfer outside the original training distribution.
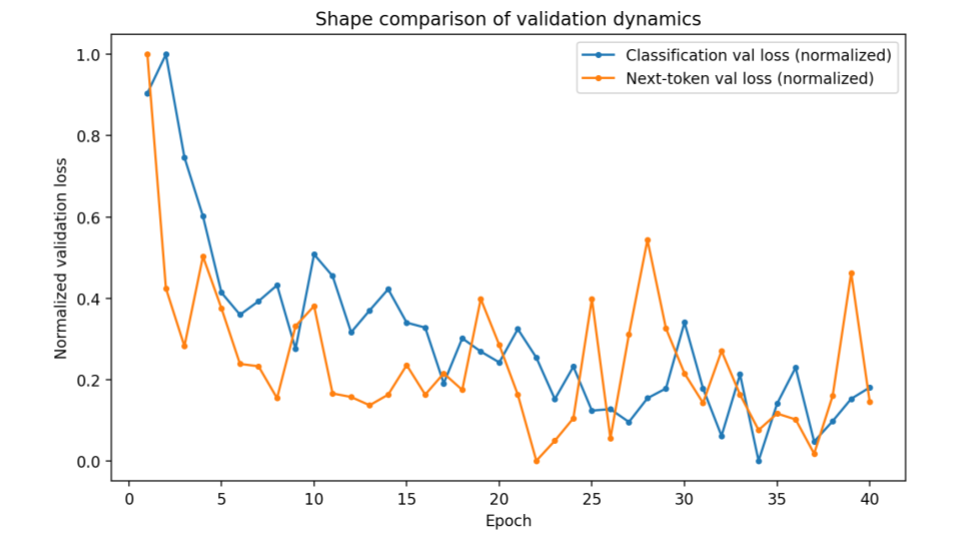
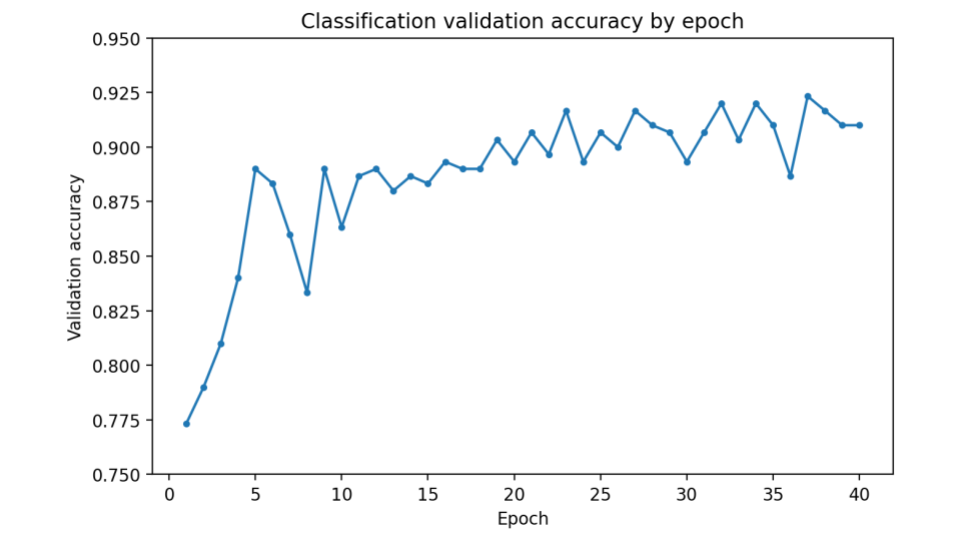
High in-distribution performance
Validation accuracy exceeds 90%, suggesting successful memorization of training dynamics.
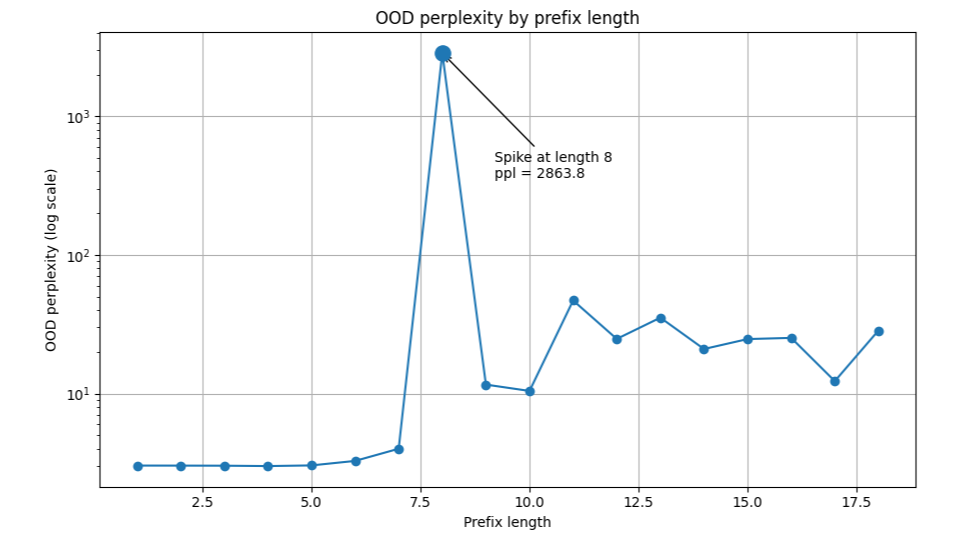
Sharp OOD failure
A dramatic perplexity spike appears immediately beyond the training boundary, indicating failure to generalize algorithmically.
Key Observation
PERFORMANCE
IS NOT
UNDERSTANDING
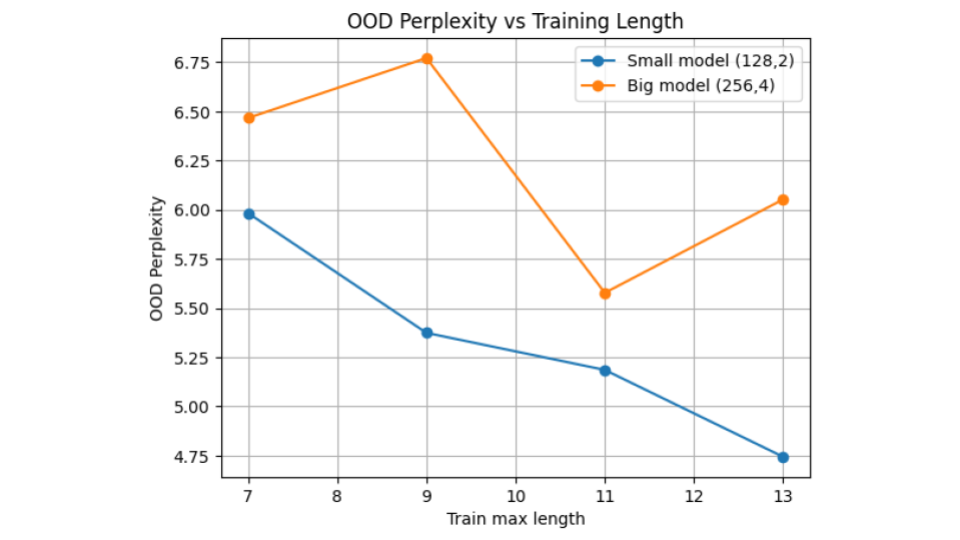
Scaling Analysis
Larger models do not consistently solve the problem.
Increasing parameter count alone fails to guarantee stronger structural generalization. Longer training contexts improve OOD performance more reliably than naive scaling.
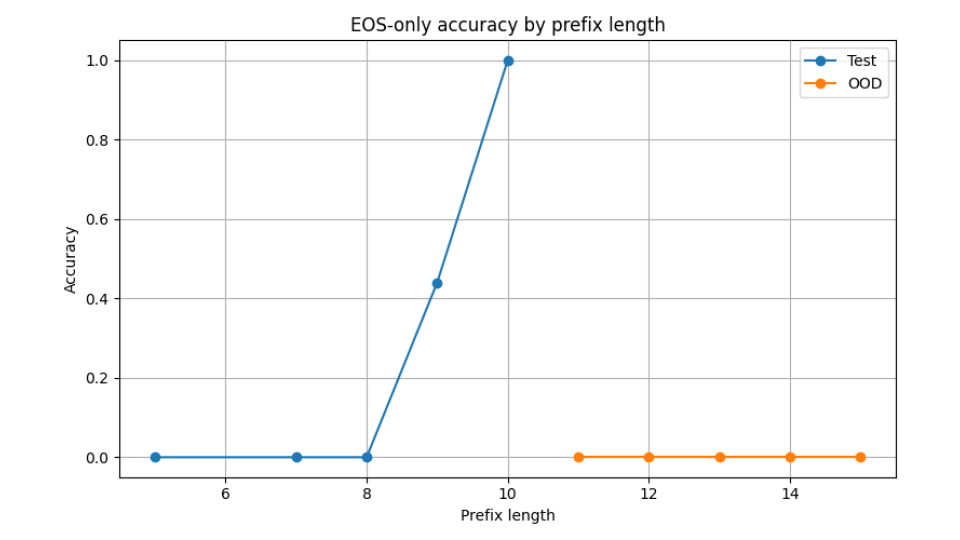
EOS prediction collapse
End-of-sequence prediction deteriorates sharply outside the training range.
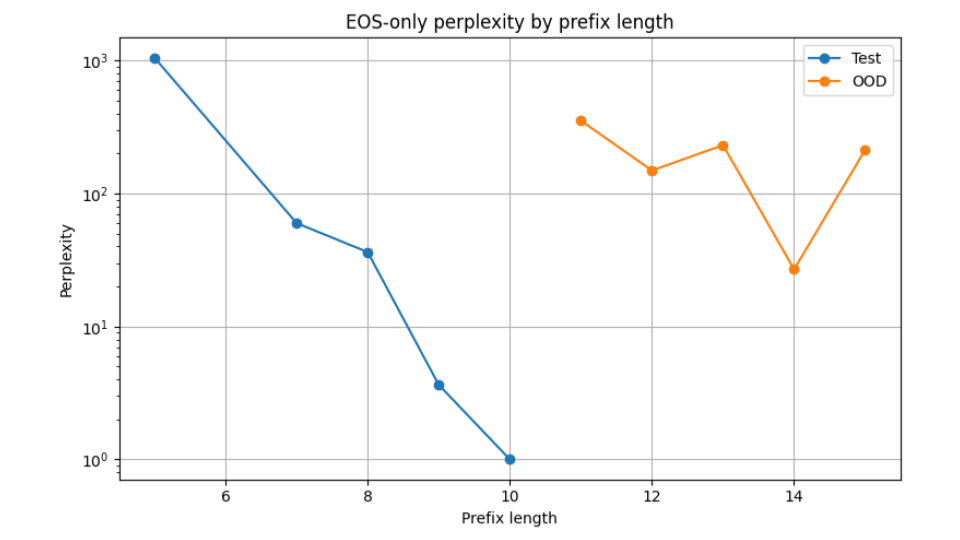
Perplexity instability
The model exhibits severe uncertainty once sequence lengths exceed familiar contexts.
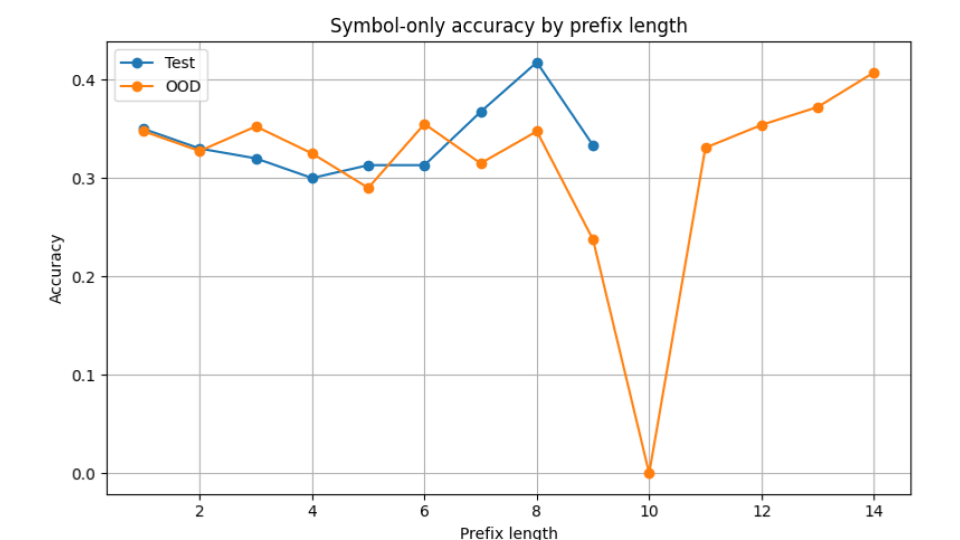
Local token prediction survives
Symbol-level prediction remains relatively stable, suggesting dependence on local statistical cues.
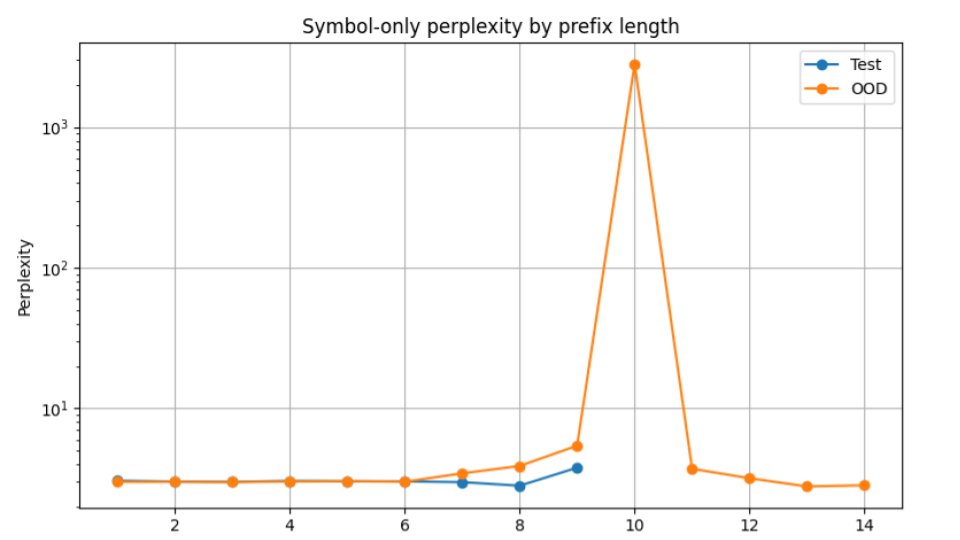
But abstraction still breaks
OOD perplexity spikes indicate that the model does not consistently recover underlying DFA structure.